극한의 애플리케이션에서 성능을 최적화해야 하는 문제에 직면한 Java 개발자라면, 이는 쉽지 않은 과제임을 잘 아실 것입니다. 이 글에서는 시스템 아키텍처를 그대로 유지하면서 약간의 코드 수정을 통해 성능을 향상시킬 수 있는 몇 가지 전략과 요령을 살펴봅니다.
극한 상황이란 무엇인가요?
이 글에서 '극한 상황’이란 반복적인 작업을 수행하거나 대량의 데이터를 처리해야 하는 애플리케이션을 의미합니다. 이러한 요구는 다양한 분야에서 흔히 발생합니다.
- 금융 애플리케이션: 금융에서는 백그라운드 작업이 수백만에서 수십억 개의 레코드를 처리하는 일이 일반적입니다.
- 머신 러닝: Java는 머신 러닝에 자주 사용되지는 않지만, 이러한 애플리케이션들은 대규모 데이터셋을 처리하는 경우가 많습니다.
- 분석: 분석 애플리케이션은 대규모 데이터셋에 접근해 보고서를 생성하는 경우가 많습니다.
HashMap
대량의 데이터를 저장하기 위해 HashMap을 생성할 때는 문자열 대신 숫자 필드를 키로 사용하는 것이 좋습니다. 이를 설명하기 위해 각 키 유형에 대해 요소를 추가하는 경우와 요소를 액세스하는 경우를 비교해 보겠습니다.
아래 차트는 String 키와 Integer 키를 사용해 HashMap에 엔트리를 추가할 때의 실행 시간을 비교합니다. x축은 HashMap에 추가된 레코드 수를 나타내고, y축은 해당 작업을 100회 반복하는 데 소요된 시간을 나타냅니다.
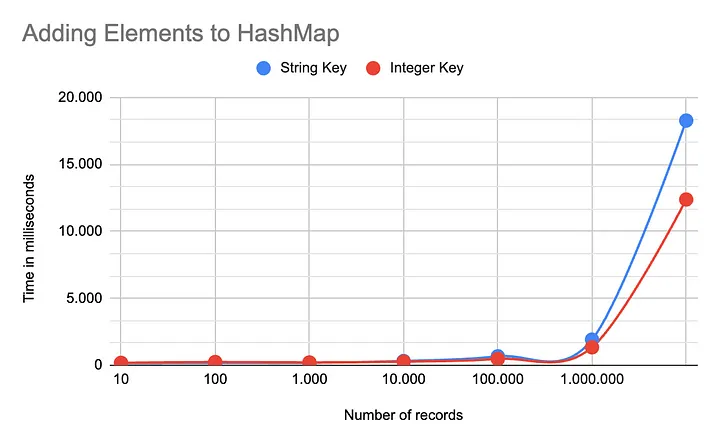
Java는 HashMap 작업 처리에서 최적화된 성능을 보여주며, 특히 백만 개의 엔트리까지는 키 유형과 상관없이 일관된 성능을 유지합니다. 이는 Java의 해시 계산 메커니즘이 내부 구조에 숫자 값을 사용해 효율적으로 엔트리를 배치하기 때문입니다.
그러나 백만 개 이상의 엔트리를 처리하는 극한 상황에서는 성능 저하가 나타납니다. 이는 해시 함수가 서로 다른 엔트리에 대해 동일한 값을 생성하여, HashMap 내부에서 해시 충돌을 해결하기 위한 추가 처리가 발생하기 때문입니다. 특히 문자열 키를 사용할 때 이러한 성능 저하가 더 두드러집니다.
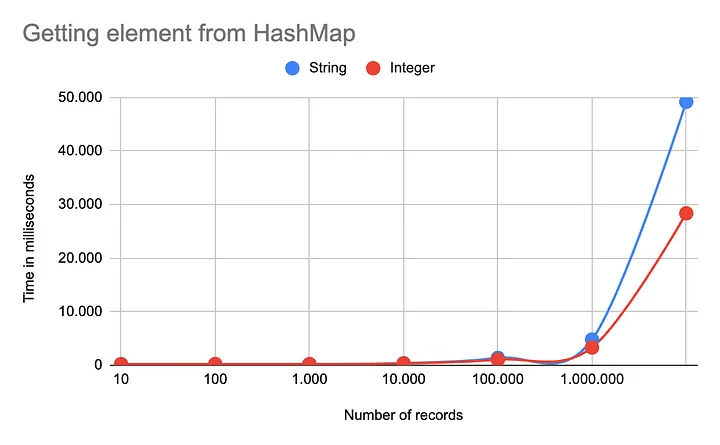
HashMap에서 요소를 액세스하기 위해 get 메서드를 사용할 때도 유사한 성능 패턴을 보이며, 이는 큰 데이터셋이나 해시 충돌을 처리할 때 성능 저하가 나타나는 현상을 반영합니다.
BigDecimal vs BigInteger vs Long vs long
Java에서 대규모 데이터셋을 처리할 때는 수치 연산이 필요하며, 다양한 요구에 맞게 여러 데이터 타입을 제공합니다.
- long: -2⁶³에서 2⁶³ - 1 사이의 정수를 저장할 수 있는 기본 타입입니다.
- Long: long 타입의 박싱된 객체 타입입니다.
- BigDecimal: 높은 정밀도로 큰 소수 값을 저장하기 위한 클래스입니다.
- BigInteger: long의 범위를 초과하는 큰 정수를 처리하기 위한 클래스입니다.
금융이나 과학적 데이터 처리를 위해서는 정확한 소수 계산이 필요하므로 BigDecimal을 사용하는 것이 권장됩니다. 그러나 비소수 연산에서는 long, Long, BigInteger를 상황에 맞게 사용할 수 있습니다.
다음 차트는 각 데이터 타입으로 100만 개 요소를 생성했을 때의 메모리 사용량을 보여줍니다.
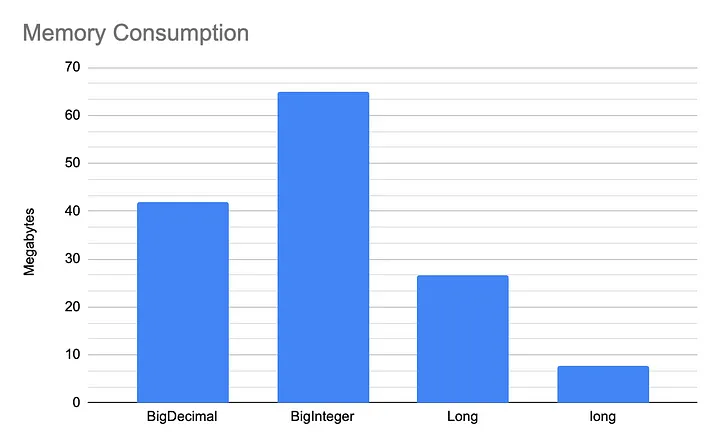
메모리 사용량 비교를 보면 Long(박싱된 타입), long(기본 타입), BigInteger 사이에 큰 차이가 있음을 알 수 있습니다. 특히 BigInteger로 100만 개 요소를 생성하면 60MB 이상의 메모리가 소모되지만, long을 사용하면 10MB 미만으로 메모리가 필요합니다. 이는 대규모 데이터셋을 처리하는 애플리케이션에서 메모리 할당을 고려해야 하는 중요성을 강조합니다.
리스트 정렬
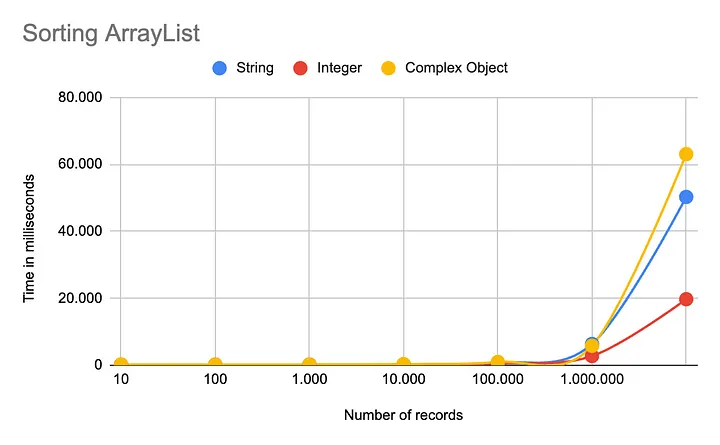
Java는 효율적인 리스트 정렬로 잘 알려져 있지만, 몇 가지 고려 사항이 필요합니다. 여기서는 String을 비교 필드로 사용하는 리스트, Integer를 사용하는 리스트, 그리고 복잡한 객체(Complex Object)를 사용하는 리스트의 정렬 시간을 살펴보겠습니다. 각 리스트 유형(ArrayList, LinkedList, Vector)을 분석합니다.
ArrayList 중에서는 Integer 비교를 기반으로 한 정렬이 특히 백만 개 이상의 요소를 가진 리스트에서 빠른 성능을 보입니다. 반면, 복잡한 객체를 포함한 리스트의 정렬은 다른 유형에 비해 느립니다.
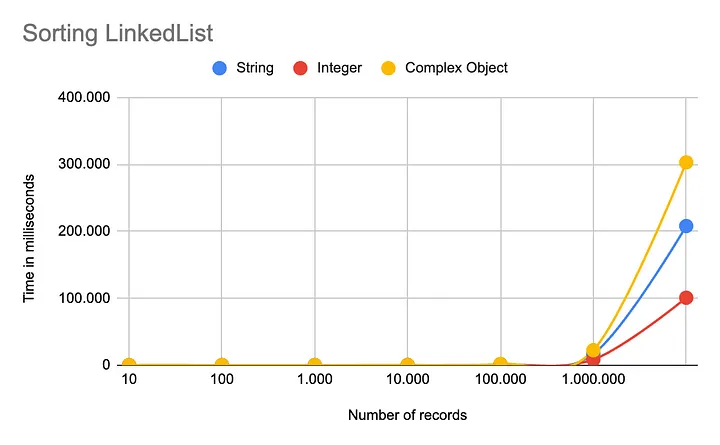
아래 차트는 ArrayList 대신 LinkedList를 사용한 경우를 비교한 것입니다. 동작은 일관되지만, Integer를 비교 기준으로 한 리스트의 정렬이 백만 개 이상의 요소를 처리할 때 더 빠르게 수행됩니다. 또한, ArrayList에 비해 전반적으로 실행 시간이 느린 점도 주목할 만합니다.
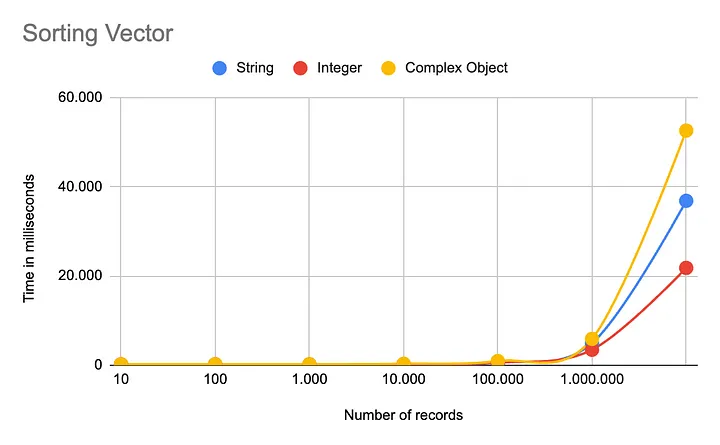
이번에는 종종 개발에서 간과되는 Java 리스트인 Vector를 살펴보겠습니다. 이전 비교와 유사한 패턴을 보이지만, Vector가 속도 면에서 다른 두 리스트보다 더 우수한 성능을 보여 다소 놀라운 결과를 나타냈습니다.
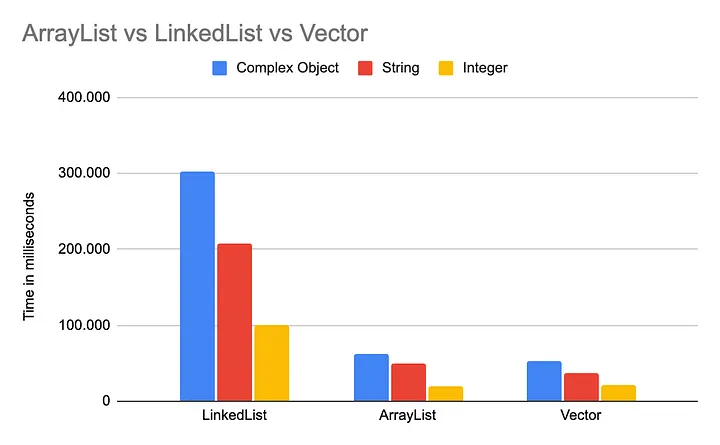
String, Integer, Complex Object를 사용하여 1000만 개 요소를 정렬하는 데 걸린 시간을 비교한 후 다음과 같은 결론을 도출할 수 있습니다.
- LinkedList는 긴 리스트를 정렬할 때 느린 성능을 보였습니다.
- Vector는 정렬 시 가장 빠른 리스트 구현으로 나타났습니다.
- 숫자, 특히 Integer를 정렬하는 것이 다른 데이터 타입을 정렬하는 것보다 더 빠릅니다.
결론
대량의 데이터를 처리하는 애플리케이션을 개발할 때 성능 최적화는 매우 중요한 과제입니다. 적절한 Java 리스트 구현을 선택하면 성능을 크게 향상시킬 수 있으며, 적절한 데이터 타입을 선택하면 시스템 성능을 향상시키는 동시에 메모리도 절약할 수 있습니다.
이 글에서는 대규모 데이터를 처리하는 애플리케이션에서 데이터 타입과 Java 리스트 구현을 신중하게 선택하는 것이 중요하다는 점을 강조했습니다. 처리하는 요소가 수천 개에 불과한 경우에는 성능 향상이 큰 의미가 없을 수 있으므로, 이러한 선택을 신중하게 고려해야 합니다.
많은 경우, Java 구현을 단순히 변경하는 것만으로는 시스템 아키텍처를 수정하거나 데이터베이스 쿼리를 최적화하는 것만큼 큰 성능 향상을 기대하기 어렵습니다. 적절한 데이터 타입과 리스트 구현을 선택하는 것도 중요하지만, 전반적인 아키텍처적 고려가 성능에 더 큰 영향을 미칠 수 있습니다.